




合作客戶/
拜耳公司 |
同濟大學 |
聯合大學 |
美國保潔 |
美國強生 |
瑞士羅氏 |






相關新聞Info
推薦新聞Info
-
> 利用溶液的張力,設計一種用于精密分區腐蝕又不接觸晶圓表面的隔離網筒
> 拉脫法測量:不同性能磁性液體的磁表面張力變化規律與影響因素(二)
> 拉脫法測量:不同性能磁性液體的磁表面張力變化規律與影響因素(一)
> 表面張力和接觸角對塑料熔體在微型通道內的流變行為的影響(二)
> 表面張力和接觸角對塑料熔體在微型通道內的流變行為的影響(一)
> 表面張力的生物醫學領域的具體應用
> 內壓力是什么意思?液體表面張力與內壓力的區別與定量關系
> 不同溫度下陰-非離子雙子星座表面活性劑表面張力的變化
> 常見多元醇(乙二醇、甘油、季戊四醇、山梨醇等)在化妝品中的作用
> 山茶油改性方法、制備原理及在水劑型化妝品中的應用(二)
使用深度學習方法高通量預測代謝酶的 kcat,或揭開細胞工廠秘密
來源:ScienceAI 瀏覽 918 次 發布時間:2022-09-14
酶周轉數(kcat)是了解細胞代謝、蛋白質組分配和生理多樣性的關鍵,但實驗測量的kcat數據往往稀疏且嘈雜。
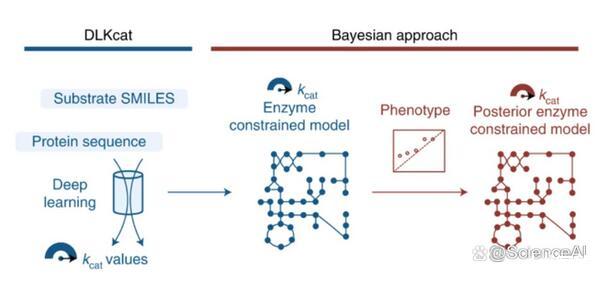
查爾姆斯理工大學(Chalmers University of Technology)的研究團隊提供了一種深度學習方法(DLKcat),用于僅根據底物結構和蛋白質序列對來自任何生物體的代謝酶進行高通量kcat預測。DLKcat可以捕獲突變酶的kcat變化并識別對kcat值有強烈影響的氨基酸殘基。研究人員應用這種方法來預測300多種酵母物種的基因組規模kcat值。
此外,該團隊設計了一個貝葉斯管道,以根據預測的kcat值參數化酶約束的基因組規模代謝模型。由此產生的模型在預測表型和蛋白質組方面優于先前管道中相應的原始酶約束基因組規模代謝模型,并使研究人員能夠解釋表型差異。DLKcat和酶約束的基因組規模代謝模型構建管道是揭示酶動力學和生理多樣性的全球趨勢,并進一步闡明大規模細胞代謝的寶貴工具。
該研究以「Deep learning-based kcat prediction enables improved enzyme-constrained model reconstruction」為題,于2022年6月16日發布在《Nature Catalysis》。

酶轉換數(kcat)定義了反應的最大化學轉化率,是了解特定生物體的新陳代謝、蛋白質組分配、生長和生理學的關鍵參數。酶數據庫BRENDA和SABIO-RK中有大量可用的kcat值集合,然而,與現有的各種生物體和代謝酶相比,這些值仍然稀少,這主要是因為缺乏用于kcat測量的高通量方法。
此外,由于不同的測定條件(例如pH值、輔因子可用性和實驗方法),實驗測量的kcat值具有相當大的可變性。總之,稀疏的收集和相當大的噪聲限制了kcat數據在全局分析中的使用,并可能掩蓋酶進化趨勢。
特別是酶約束的基因組規模代謝模型(ecGEM),其中全細胞代謝網絡受到酶催化能力的約束,因此能夠準確模擬最大生長能力、代謝變化和蛋白質組分配,特別依賴于基因組-縮放kcat值。在過去的十年中,ecGEM(或遵循酶約束概念的模型)已分別針對幾種經過充分研究的生物體開發,包括大腸桿菌、釀酒酵母、中國倉鼠卵巢細胞和智人。由于kcat測量的局限性和依賴酶委員會(EC)編號注釋來搜索這些已開發管道中的kcat值,為研究較少的生物體重建ecGEM或為多種生物體進行大規模重建仍然是一個挑戰。
此外,即使對于那些經過充分研究的生物,kcat的覆蓋范圍也遠未完成。在釀酒酵母ecGEM中,只有5%的酶促反應在BRENDA中具有完全匹配的kcat值。當數據缺失時,以前的ecGEM重建流程通常假設kcat值來自類似的底物、反應或其他生物,這可能導致模型預測偏離實驗觀察。明確要求獲得大規模的kcat值以提高模型準確性并產生更可靠的表型模擬。
深度學習已被應用并在模擬化學空間、基因表達、酶相關參數(如酶親和力和EC數)方面表現出出色的性能。此前,有研究人員采用機器學習方法,根據從蛋白質結構中獲得的平均代謝通量和催化位點等特征來預測大腸桿菌kcat值。然而,這些特征通常很難獲得,這使得這種方法只能應用于研究最充分的生物體,如大腸桿菌。
在這里,查爾姆斯理工大學(Chalmers University of Technology)的研究團隊提出了深度學習方法DLKcat來預測所有代謝酶與其底物的kcat值,只需要底物SMILES信息和酶的蛋白質序列作為輸入,從而為任何物種產生通用的kcat預測工具。
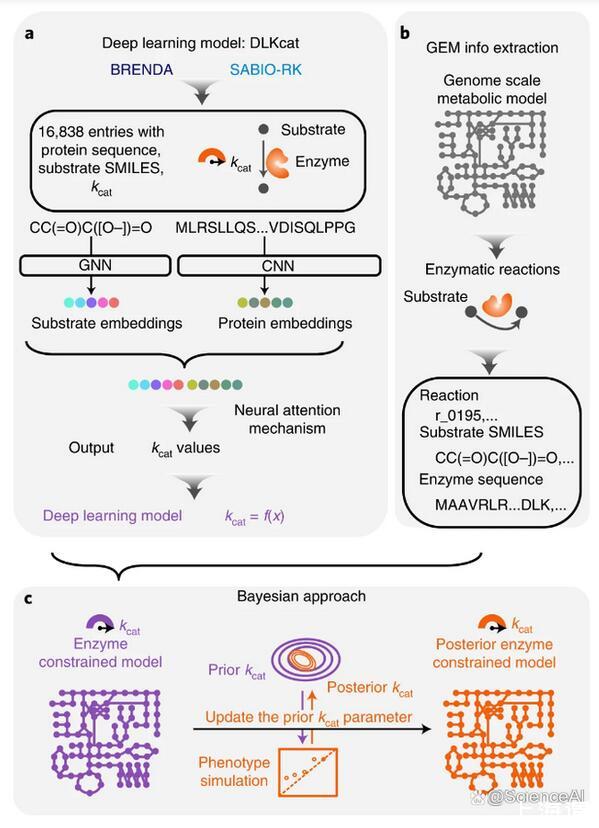
圖示:用于ecGEM參數化的kcat深度學習。(來源:論文)
DLKcat可以捕獲kcat向精確的單個氨基酸替代方向的變化,從而能夠計算注意力權重,從而識別對酶活性產生重大影響的氨基酸殘基。氨基酸取代是酶進化領域的一項強大技術,通常用于探測酶催化機制。特別是,大多數替代實驗在底物結合位點區域進行誘變,因為假設結合區域將對催化活性產生很大影響。然而,據報道,偏遠地區會對催化活性產生深遠影響。
研究人員不僅確定了人PNP酶肌苷結合區域中氨基酸殘基的高關注權重,而且還確定了具有高關注權重的各種非結合殘基位點,這表明這些殘基也可能對催化活性產生重大影響,值得進一步驗證。DLKcat因此可以作為蛋白質工程工具箱的重要組成部分。
預測的基因組規模的kcat譜可以促進酶約束代謝模型的重建,從策劃和自動生成的基本(非ec)GEM中。事實證明,深度學習預測的kcat過程比匹配來自BRENDA和SABIO-RK數據庫的體外kcat值更全面但仍然實用;這在GECKO和MOMENT等原始ecGEM重建管道中很常見。
通過不依賴EC編號注釋,DLKcat還能夠預測同工酶特異性kcat值,而SMILES的使用避免了原始ecGEM重建管道可能遇到的GEM和BRENDA之間底物命名不統一的問題。隨后可以通過貝葉斯方法將DL-ecGEM調整為現有的實驗生長數據,該方法產生具有生理相關解空間的后均值ecGEM。結合起來,當前基于DLKcat的管道因此適用于幾乎任何生物體的ecGEM重建,其中蛋白質序列FASTA文件和基本GEM可用。他們的管道因此提高了適用性,與以前構建的原始ecGEM相比,它甚至提高了具有酶促約束的反應數量。
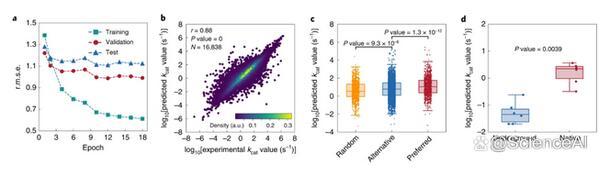
圖示:kcat預測的深度學習模型性能。(來源:論文)
盡管基于DLKcat的管道產生的ecGEM性能優于原始ecGEM,但仍然存在各種挑戰。例如,雖然深度學習模型可以將混雜酶的替代物與隨機選擇的底物區分開來,但它仍然預測了可能過高的隨機底物的動力學活性水平。
這種行為可以通過負面數據的有限可用性來解釋:酶-底物對沒有產生催化作用的情況。增加對陰性數據集的報告,其中酶-底物對的未檢測到的活性由酶數據庫報告和收集,可以增強未來深度學習模型在定義真陰性方面的能力。
此外,DLKcat并未考慮pH和溫度等環境因素的影響,但將DLKcat與其他新興機器學習工具(例如酶的最佳溫度預測)相結合,將有助于未來研究環境參數對酶活性的影響。
另一個挑戰涉及涉及多種底物和由異聚酶復合物催化的反應。可以為此類反應定義的多底物SMILES和蛋白質序列都可以與DLKcat一起發揮作用,從而為一個反應產生多個預測的kcat值。目前在這些情況下,研究人員會選擇最大kcat值,但最好設計一種方法來預測每種多底物和異聚酶的一個kcat值。
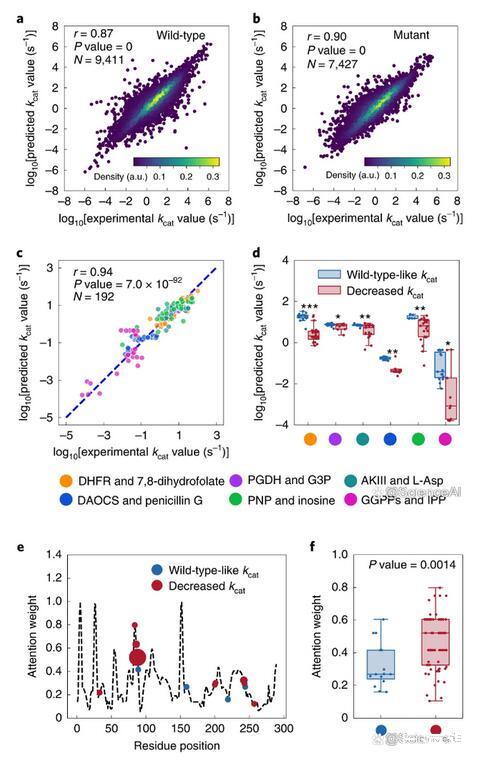
圖示:用于預測和解釋突變酶kcat的深度學習模型。(來源:論文)
此外,DLKcat衍生的DL-ecGEM和后驗均值ecGEM繼承了基本GEM的局限性,其中基于約束的建模的核心穩態假設允許人們確定代謝通量,但不容易考慮調節行為。雖然ecGEM極大地將基于約束的模型的解空間減少到細胞可行容量,但kcat并不是決定反應速率的唯一動力學參數,例如,親和常數起著重要的作用。然而,由于基于約束的模型無法預測內部代謝物濃度,因此目前無法輕易考慮這些參數的影響。
盡管如此,kcat值也是其他資源分配模型中的重要參數,例如蛋白質組約束的GEM和代謝/大分子表達模型。盡管改進的預測和更多的應用,如何定義kcat值也仍然是重建這些模型的挑戰。這種資源分配模型和ecGEM都認為細胞需要將其有限的蛋白質組分配到不同的途徑以實現更快的生長或更好的適應度,而每個反應的蛋白質組成本同樣由酶的通量和動力學速率定義。
因此,這些模型的代謝部分的深度學習預測kcat值可以提高其質量和性能,盡管無法從DLKcat獲得在這些模型公式中確定的其他具有挑戰性的動力學參數,例如核糖體催化率。此外,特別關注描述酶動力學的模型公式可以受益于深度學習預測的kcat值,因此DLKcat方法可以在建模領域找到廣泛的應用。
總之,DLKcat產生了現實的kcat值,可用于指導未來的基因工程、了解酶進化和重建ecGEM以預測代謝通量和表型。除此之外,這種基于深度學習的kcat預測工具的許多其他潛在用途,例如基因組挖掘和全基因組關聯研究分析中的工具。開發的自動貝葉斯ecGEM重建管道將有助于進一步用于ecGEM重建,用于組學數據合并和分析。
論文鏈接:https://www.nature.com/articles/s41929-022-00798-z